前言
排序算法是数组相关算法的基础知识之一,它们的经典思想可以用于很多算法之中。这里详细介绍和总结 7 种最常见排序算法,并用 Go 做了实现,同时对比这几种算法的时间复杂度、空间复杂度和稳定性 。后一部分是对 Go 标准库排序实现的源码阅读和分析, 理解官方是如何通过将以上排序算法进行组合来提高排序性能,完成生产环境的排序实践。
排序算法分类
常见的这 7 种排序算法分别是:
- 选择排序
- 冒泡排序
- 插入排序
- 希尔排序
- 归并排序
- 快速排序
- 堆排序
我们可以根据算法特点像复杂度、是否比较元素、内外部排序等特点对它们做分类,比如上面的算法都是内部排序的。一般可以基于算法是否比较了元素,将排序分为两类:
- 比较类排序:通过比较来决定元素间的相对次序。由于其平均时间复杂度不能突破$O(N\log N)$,因此也称为非线性时间比较类排序。
- 非比较类排序:不通过比较来决定元素间的相对次序。它可以突破基于比较排序的时间下界,以线性时间运行,因此也称为线性时间非比较类排序。主要实现有: 桶排序、计数排序和基数排序。
通过这个的分类,可以先有一个基本的认识,就是比较类排序算法的平均时间复杂度较好的情况下是 $O(N\log N)$(一遍找元素 $O(N)$,一遍找位置$O(\log N)$)。
注: 有重复大量元素的数组,可以通过三向切分快速排序, 将平均时间复杂度降低到 $O(N)$
比较类排序算法
因为非比较排序有其局限性,所以它们并不常用。本文将要介绍的 7 种算法都是比较类排序。
选择排序
原理:遍历数组, 从中选择最小元素,将它与数组的第一个元素交换位置。继续从数组剩下的元素中选择出最小的元素,将它与数组的第二个元素交换位置。循环以上过程,直到将整个数组排序。
时间复杂度分析:$O(N^{2})$。选择排序大约需要 $N^{2}/2$ 次比较和 $N$ 次交换,它的运行时间与输入无关,这个特点使得它对一个已经排序的数组也需要很多的比较和交换操作。
实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| // 选择排序 (selection sort)
package sorts
func SelectionSort(arr []int) []int {
for i := 0; i < len(arr); i++ {
min := i
for j := i + 1; j < len(arr); j++ {
if arr[j] < arr[min] {
min = j
}
}
tmp := arr[i]
arr[i] = arr[min]
arr[min] = tmp
}
return arr
}
|
冒泡排序
原理:遍历数组,比较并将大的元素与下一个元素交换位置, 在一轮的循环之后,可以让未排序i的最大元素排列到数组右侧。在一轮循环中,如果没有发生元素位置交换,那么说明数组已经是有序的,此时退出排序。
时间复杂度分析: $O(N^{2})$
实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| // 冒泡排序 (bubble sort)
package sorts
func bubbleSort(arr []int) []int {
swapped := true
for swapped {
swapped = false
for i := 0; i < len(arr)-1; i++ {
if arr[i+1] < arr[i] {
arr[i+1], arr[i] = arr[i], arr[i+1]
swapped = true
}
}
}
return arr
}
|
插入排序
原理:数组先看成两部分,排序序列和未排序序列。排序序列从第一个元素开始,该元素可以认为已经被排序。遍历数组, 每次将扫描到的元素与之前的元素相比较,插入到有序序列的适当位置。
时间复杂度分析:插入排序的时间复杂度取决于数组的排序序列,如果数组已经部分有序了,那么未排序元素较少,需要的插入次数也就较少,时间复杂度较低。
- 平均情况下插入排序需要 $N^{2}/4$ 次比较以及 $N^{2}/4$ 次交换;
- 最坏的情况下需要 $N^{2}/2$ 比较以及 $N^{2}/2$ 次交换,最坏的情况是数组都是未排序序列(倒序)的;
- 最好的情况下需要 $ N-1$ 次比较和 0 次交换,最好的情况就是数组已经是排序序列。
实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| // 插入排序 (insertion sort)
package sorts
func InsertionSort(arr []int) []int {
for currentIndex := 1; currentIndex < len(arr); currentIndex++ {
temporary := arr[currentIndex]
iterator := currentIndex
for ; iterator > 0 && arr[iterator-1] >= temporary; iterator-- {
arr[iterator] = arr[iterator-1]
}
arr[iterator] = temporary
}
return arr
}
|
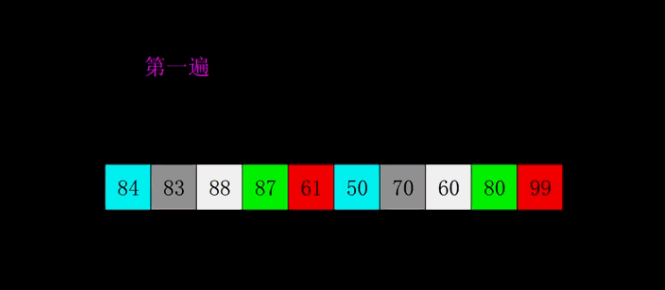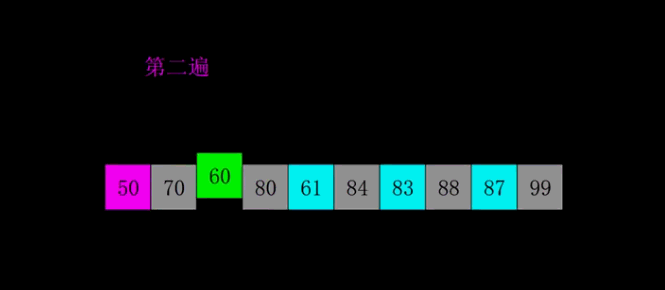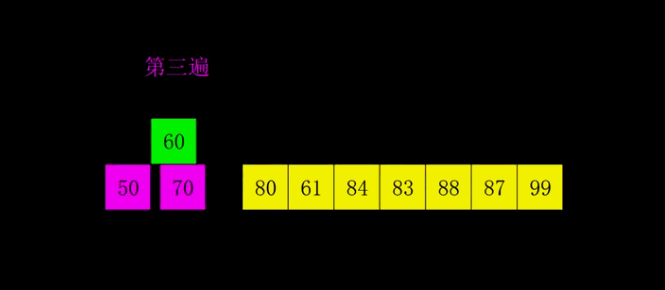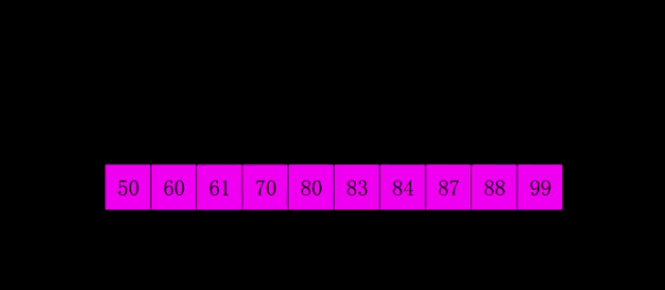
希尔排序
原理:希尔排序,也称递减增量排序算法,实质是插入排序的优化(分组插入排序)。对于大规模的数组,插入排序很慢,因为它只能交换相邻的元素位置,每次只能将未排序序列数量减少 1。希尔排序的出现就是为了解决插入排序的这种局限性,通过交换不相邻的元素位置,使每次可以将未排序序列的减少数量变多。
希尔排序使用插入排序对间隔 d 的序列进行排序。通过不断减小 d,最后令 d=1,就可以使得整个数组是有序的。
时间复杂度:$O(dN*M)$, M 表示已排序序列长度,d 表示间隔, 即 N 的若干倍乘于递增序列的长度
实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
| // 希尔排序 (shell sort)
package sorts
func ShellSort(arr []int) []int {
for d := int(len(arr) / 2); d > 0; d /= 2 {
for i := d; i < len(arr); i++ {
for j := i; j >= d && arr[j-d] > arr[j]; j -= d {
arr[j], arr[j-d] = arr[j-d], arr[j]
}
}
}
return arr
}
|
归并排序
原理: 将数组分成两个子数组, 分别进行排序,然后再将它们归并起来(自上而下)。
具体算法描述:先考虑合并两个有序数组,基本思路是比较两个数组的最前面的数,谁小就先取谁,取了后相应的指针就往后移一位。然后再比较,直至一个数组为空,最后把另一个数组的剩余部分复制过来即可。
再考虑递归分解,基本思路是将数组分解成left和right,如果这两个数组内部数据是有序的,那么就可以用上面合并数组的方法将这两个数组合并排序。如何让这两个数组内部是有序的?可以二分,直至分解出的小组只含有一个元素时为止,此时认为该小组内部已有序。然后合并排序相邻二个小组即可。
归并算法是分治法 的一个典型应用, 所以它有两种实现方法:
- 自上而下的递归: 每次将数组对半分成两个子数组再归并(分治)
- 自下而上的迭代:先归并子数组,然后成对归并得到的子数组
时间复杂度分析: $O(N\log N)$
实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| // 归并排序 (merge sort)
package sorts
func merge(a []int, b []int) []int {
var r = make([]int, len(a)+len(b))
var i = 0
var j = 0
for i < len(a) && j < len(b) {
if a[i] <= b[j] {
r[i+j] = a[i]
i++
} else {
r[i+j] = b[j]
j++
}
}
for i < len(a) {
r[i+j] = a[i]
i++
}
for j < len(b) {
r[i+j] = b[j]
j++
}
return r
}
// Mergesort 合并两个数组
func Mergesort(items []int) []int {
if len(items) < 2 {
return items
}
var middle = len(items) / 2
var a = Mergesort(items[:middle])
var b = Mergesort(items[middle:])
return merge(a, b)
}
|
快速排序
原理:快速排序也是分治法的一个应用,先随机拿到一个基准 pivot,通过一趟排序将数组分成两个独立的数组,左子数组小于或等于 pivot,右子数组大于等于 pivot。 然后可在对这两个子数组递归继续以上排序,最后使整个数组有序。
具体算法描述:
- 从数组中挑选一个切分元素,称为“基准” (pivot)
- 排序数组,把所有比基准值小的元素排到基准前面,所有比基准值大的元素排到基准后面(相同元素不对位置做要求)。这个排序完成后,基准就排在数组的中间位置。这个排序过程称为“分区” (partition)
- 递归地把小于基准值元素的子数组和大于基准值的子数组排序
空间复杂度分析:快速排序是原地排序,不需要辅助数据,但是递归调用需要辅助栈,最好情况下是递归 $\log 2N$ 次,所以空间复杂度为 $O(\log 2N)$,最坏情况下是递归 $N-1$次,所以空间复杂度是 $O(N)$。
时间复杂度分析:
- 最好的情况是每次基准都正好将数组对半分,这样递归调用最少,时间复杂度为 $O(N \log N)$
- 最坏的情况是每次分区过程,基准都是从最小元素开始,对应时间复杂度为 $O(N^{^{2}})$
算法改进:
- 分区过程中更合理地选择基准(pivot)。直接选择分区的第一个或最后一个元素做 pivot 是不合适的,对于已经排好序,或者接近排好序的情况,会进入最差情况,时间复杂度为 $O(N^{2})$
- 因为快速排序在小数组中也会递归调用自己,对于小数组,插入排序比快速排序的性能更好,因此在小数组中可以切换到插入排序
- 更快地分区(三向切分快速排序):对于有大量重复元素的数组,可以将数组切分为三部分,分别对应小于 pivot、等于 pivot 和大于 pivot 切分元素
实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| // 三向切分快速排序 (quick sort)
package sorts
import (
"math/rand"
)
func QuickSort(arr []int) []int {
if len(arr) <= 1 {
return arr
}
pivot := arr[rand.Intn(len(arr))]
lowPart := make([]int, 0, len(arr))
highPart := make([]int, 0, len(arr))
middlePart := make([]int, 0, len(arr))
for _, item := range arr {
switch {
case item < pivot:
lowPart = append(lowPart, item)
case item == pivot:
middlePart = append(middlePart, item)
case item > pivot:
highPart = append(highPart, item)
}
}
lowPart = QuickSort(lowPart)
highPart = QuickSort(highPart)
lowPart = append(lowPart, middlePart...)
lowPart = append(lowPart, highPart...)
return lowPart
}
|
堆排序
原理:堆排序是利用“堆积”(heap)这种数据结构的一种排序算法。因为堆是一个近似完全二叉树结构,满足子节点的键值或索引小于(或大于)它的父节点。
具体算法描述:
- 将待排序数组构建成大根堆,这个堆为初始的无序区
- 将堆顶元素 $R_{1}$ 与最后一个元素 $R_{n}$ 交换,此时得到新的无序区($R_{1},R_{2},…R_{n-1}$)和新的有序区($R_{n}$),并且满足 $R_{1,2,…n-1}<= R_{n}$
- 由于交换后新的堆顶 $R_{1}$可能违反堆的性质,需要对当前无序区调整为新堆,然后再次将 $R_{1}$与无序区最后一个元素交换,得到新的无序区 $R_{1},R_{2}…R_{n-2}$ 和新的有序区$R_{n-1},R_{n}$。不断重复此过程直到有序区的元素个数为$n-1$,则整个排序过程完成
时间复杂度分析:一个堆的高度为 $\log N$,因此在堆中插入元素和删除最大元素的时间复杂度为 $O(\log N)$。堆排序会对 N 个节点进行下沉操作,因为时间复杂度为 $O(N \log N)$

实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| // 堆排序 (heap sort)
package sorts
type maxHeap struct {
slice []int
heapSize int
}
func buildMaxHeap(slice []int) maxHeap {
h := maxHeap{slice: slice, heapSize: len(slice)}
for i := len(slice) / 2; i >= 0; i-- {
h.MaxHeapify(i)
}
return h
}
func (h maxHeap) MaxHeapify(i int) {
l, r := 2*i+1, 2*i+2
max := i
if l < h.size() && h.slice[l] > h.slice[max] {
max = l
}
if r < h.size() && h.slice[r] > h.slice[max] {
max = r
}
if max != i {
h.slice[i], h.slice[max] = h.slice[max], h.slice[i]
h.MaxHeapify(max)
}
}
func (h maxHeap) size() int { return h.heapSize }
func HeapSort(slice []int) []int {
h := buildMaxHeap(slice)
for i := len(h.slice) - 1; i >= 1; i-- {
h.slice[0], h.slice[i] = h.slice[i], h.slice[0]
h.heapSize--
h.MaxHeapify(0)
}
return h.slice
}
|
算法复杂度比较
下面是各排序算法的复杂度和稳定性比较:
| 排序算法 | 时间复杂度(平均) | 时间复杂度(最好) | 时间复杂度(最坏) | 空间复杂度 | 稳定性 | 备注 |
|---|
| 选择排序 | $O(N^{2})$ | $O(N^{2})$ | $O(N^{2})$ | $O(1)$ | 不稳定 | |
| 冒泡排序 | $O(N^{2})$ | $O(N)$ | $O(N^{2})$ | $O(1)$ | 稳定 | |
| 插入排序 | $O(N^{2})$ | $O(N)$ | $O(N^{2})$ | $O(1)$ | 稳定 | 时间复杂度和初始顺序有关 |
| 希尔排序 | $O(N^{1.3})$ | $O(N)$ | $O(N^{2})$ | $O(1)$ | 不稳定 | 改进版插入排序 |
| 归并排序 | $O(N \log N)$ | $O(N \log N)$ | $O(N \log N)$ | $O(N)$ | 稳定 | |
| 快速排序 | $O(N \log N)$ | $O(N \log N)$ | $O(N^{2})$ | $O(N \log N)$ | 不稳定 | |
| 堆排序 | $O(N \log N)$ | $O(N \log N)$ | $O(N \log N)$ | $O(1)$ | 不稳定 | 无法利用局部性原理 |
注:
- 稳定:如果 a 原本在 b 前面,而 a=b,排序之后 a 仍然在 b 的前面。
- 不稳定:如果 a 原本在 b 的前面,而 a=b,排序之后 a 可能会出现在 b 的后面。
对比这里排序的时间复杂度,归并排序、快速排序和堆排序的平均时间复杂度都是 $O(N \log N)$。但是再比较最坏的情况, 可以看到堆排序的下界也是 $O(N \log N)$,而快排最坏的时间复杂度是 $O(N^{2})$。 你可能会问,按分析结果来说,堆排序应该是实际使用的更好选择,但为什么业界的排序实现更多是快速排序?
实际上在算法分析中,大 $O$ 的作用是给出一个规模的下界,而不是增长数量的下界。因此,算法复杂度一样只是说明随着数据量的增加,算法时间代价增长的趋势相同,并不是执行的时间就一样,这里面有很多常量参数的差别,比如在公式里各个排序算法的前面都省略了一个$c$,这个$c$ 对于堆排序来说是100,可能对于快速排序来说就是10,但因为是常数级所以不影响大 $O$。
这里有一份平均排序时间的 Benchmark 测试数据(数据集是随机整数,时间单位 s):
| 数据规模 | 快速排序 | 归并排序 | 希尔排序 | 堆排序 |
|---|
| 1000 w | 0.75 | 1.22 | 1.77 | 3.57 |
| 5000 w | 3.78 | 6.29 | 9.48 | 26.54 |
| 1亿 | 7.65 | 13.06 | 18.79 | 61.31 |
因为堆排序每次取一个最大值和堆底部的数据交换,重新筛选堆,把堆顶的X调整到位,有很大可能是依旧调整到堆的底部(堆的底部X显然是比较小的数,才会在底部),然后再次和堆顶最大值交换,再调整下来,可以说堆排序做了许多无用功。
总结起来就是,快排的最坏时间虽然复杂度高,但是在统计意义上,这种数据出现的概率极小,而堆排序过程里的交换跟快排过程里的交换虽然都是常量时间,但是常量时间差很多。
Go 标准库排序源码分析
梳理完最常用的7种排序算法后,我们继续来看下 Go 在标准库里是怎么做的排序实现。
标准库的 sort 包的目录树如下(以 Go 1.15.5为例):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| $ tree .
.
├── example_interface_test.go // 提供对 []struct 排序的 example
├── example_keys_test.go // 根据 struct 里对某一字段的自定义比较,来对 []struct 排序的 example
├── example_multi_test.go // 根据用户定义好的 less 方法做排序的 example
├── example_search_test.go // sort.Search 提供对排序数组二分查找某一元素的 example
├── example_test.go // 基本的各种数组排序的 example
├── example_wrapper_test.go // 对 sort.Interface 接口的实现 (封装),排序的 example
├── export_test.go
├── genzfunc.go
├── search.go // 二分查找的实现
├── search_test.go
├── slice.go
├── slice_go113.go
├── slice_go14.go
├── slice_go18.go
├── sort.go // 主要代码,提供对 slice 和自定义集合的排序实现
├── sort_test.go
└── zfuncversion.go
|
其中带有 example_* 前缀的文件是 sort 包的示例代码,有官方 example 来说明排序的使用方法。很有必要看一遍,可以理解 sort 包怎么使用,和在一些相对复杂场景下如何排序。
排序的主要代码在 sort.go 这个文件里。实现的排序算法有: 插入排序(insertionSort)、堆排序(heapSort)、快速排序(quickSort)、希尔排序(ShellSort)和归并排序(SymMerge)。
sort 包根据稳定性,将排序方法分为两类:不稳定排序和稳定排序
不稳定排序
不稳定排序入口函数是 Sort(data interface),为支持任意元素类型的 slice 的排序,sort 包定义了一个 Interface 接口和接受该接口参数类型的 Sort 函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| // A type, typically a collection, that satisfies sort.Interface can be
// sorted by the routines in this package. The methods require that the
// elements of the collection be enumerated by an integer index.
type Interface interface {
// Len is the number of elements in the collection.
Len() int
// Less reports whether the element with
// index i should sort before the element with index j.
Less(i, j int) bool
// Swap swaps the elements with indexes i and j.
Swap(i, j int)
}
// Sort sorts data.
// It makes one call to data.Len to determine n, and O(n*log(n)) calls to
// data.Less and data.Swap. The sort is not guaranteed to be stable.
func Sort(data Interface) {
n := data.Len()
quickSort(data, 0, n, maxDepth(n))
}
|
只要排序数组的元素类型实现了 sort.Interface , 就可以通过 sort.Sort(data)进行排序。其中 maxDepth(n) 是快排递归的最大深度,也是快排切换堆排的阈值,它的实现:
1
2
3
4
5
6
7
8
9
| // maxDepth returns a threshold at which quicksort should switch
// to heapsort. It returns 2*ceil(lg(n+1)).
func maxDepth(n int) int {
var depth int
for i := n; i > 0; i >>= 1 {
depth++
}
return depth * 2
}
|
需要注意的一点是, sort.Sort 调用的 quickSort 排序函数,并不是最常见的快排(参考本文 3.6 小节), quickSort的整体框架比较复杂,流程如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| func quickSort(data Interface, a, b, maxDepth int) {
// a是第一个索引,b 是最后一个索引。如果 slice 长度大于 12,会一周走下面排序循环
for b-a > 12 {
// 如果递归到了最大深度, 就使用堆排序
if maxDepth == 0 {
heapSort(data, a, b)
return
}
// 循环一次, 最大深度 -1, 相当于又深入(递归)了一层
maxDepth--
// 这是使用的是 三向切分快速排序,通过 doPivot 进行快排的分区
// doPivot 的实现比较复杂,a 是数据集的左边, b 是数据集的右边,
// 它取一点为轴,把不大于中位数的元素放左边,大于轴的元素放右边,
// 返回小于中位数部分数据的最后一个下标,以及大于轴部分数据的第一个下标。
// 下标位置 a...mlo,pivot,mhi...b
// data[a...mlo] <= data[pivot]
// data[mhi...b] > data[pivot]
mlo, mhi := doPivot(data, a, b)
// 避免较大规模的子问题递归调用,保证栈深度最大为 maxDepth
// 解释:因为循环肯定比递归调用节省时间,但是两个子问题只能一个进行循环,另一个只能用递归。这里是把较小规模的子问题进行递归,较大规模子问题进行循环。
if mlo-a < b-mhi {
quickSort(data, a, mlo, maxDepth)
a = mhi // i.e., quickSort(data, mhi, b)
} else {
quickSort(data, mhi, b, maxDepth)
b = mlo // i.e., quickSort(data, a, mlo)
}
}
// 如果元素的个数小于 12 个(无论是递归的还是首次进入), 就先使用希尔排序,间隔 d=6
if b-a > 1 {
// Do ShellSort pass with gap 6
// It could be written in this simplified form cause b-a <= 12
for i := a + 6; i < b; i++ {
if data.Less(i, i-6) {
data.Swap(i, i-6)
}
}
insertionSort(data, a, b)
}
}
|
这里 insertionSort 的和3.3节实现的插排的实现是一样的; heapSort 这里是构建最大堆,通过 siftDown 来对 heap 进行调整,维护堆的性质:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| // siftDown implements the heap property on data[lo, hi).
// first is an offset into the array where the root of the heap lies.
func siftDown(data Interface, lo, hi, first int) {
root := lo
for {
child := 2*root + 1
if child >= hi {
break
}
if child+1 < hi && data.Less(first+child, first+child+1) {
child++
}
if !data.Less(first+root, first+child) {
return
}
data.Swap(first+root, first+child)
root = child
}
}
func heapSort(data Interface, a, b int) {
first := a
lo := 0
hi := b - a
// Build heap with greatest element at top.
for i := (hi - 1) / 2; i >= 0; i-- {
siftDown(data, i, hi, first)
}
// Pop elements, largest first, into end of data.
for i := hi - 1; i >= 0; i-- {
data.Swap(first, first+i)
siftDown(data, lo, i, first)
}
}
|
在上面快速排序的原理我们有提到过:如果每次分区过程,基准(pivot)都是从最小元素开始,那么对应时间复杂度为$O(N^{^{2}})$ , 这是快排最差的排序场景。为避免这种情况,quickSort 里的 doPivot 选取了两个基准,进行三向切分,提高快速排序的效率:doPivot 在切分之前,先使用 medianOfThree 函数选择一个肯定不是最大和最小的值作为轴,放在了切片首位。然后把不小于 data[pivot] 的数据放在了 $[lo, b)$ 区间,把大于 data[pivot] 的数据放在了 $(c, hi-1]$ 区间(其中 data[hi-1] >= data[pivot])。即 slice 会被切分成三个区间:
$$ \left\{\begin{matrix} data[lo, b-1) \\ data[b-1, c) \\ data[c, hi) \end{matrix}\right.$$
doPivot的实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
| // Quicksort, loosely following Bentley and McIlroy,
// ``Engineering a Sort Function,'' SP&E November 1993.
// medianOfThree moves the median of the three values data[m0], data[m1], data[m2] into data[m1].
func medianOfThree(data Interface, m1, m0, m2 int) {
// sort 3 elements
if data.Less(m1, m0) {
data.Swap(m1, m0)
}
// data[m0] <= data[m1]
if data.Less(m2, m1) {
data.Swap(m2, m1)
// data[m0] <= data[m2] && data[m1] < data[m2]
if data.Less(m1, m0) {
data.Swap(m1, m0)
}
}
// now data[m0] <= data[m1] <= data[m2]
}
func doPivot(data Interface, lo, hi int) (midlo, midhi int) {
m := int(uint(lo+hi) >> 1) // Written like this to avoid integer overflow.
if hi-lo > 40 {
// Tukey's ``Ninther,'' median of three medians of three.
s := (hi - lo) / 8
medianOfThree(data, lo, lo+s, lo+2*s)
medianOfThree(data, m, m-s, m+s)
medianOfThree(data, hi-1, hi-1-s, hi-1-2*s)
}
medianOfThree(data, lo, m, hi-1)
// Invariants are:
// data[lo] = pivot (set up by ChoosePivot)
// data[lo < i < a] < pivot
// data[a <= i < b] <= pivot
// data[b <= i < c] unexamined
// data[c <= i < hi-1] > pivot
// data[hi-1] >= pivot
pivot := lo
a, c := lo+1, hi-1
for ; a < c && data.Less(a, pivot); a++ {
}
b := a
for {
for ; b < c && !data.Less(pivot, b); b++ { // data[b] <= pivot
}
for ; b < c && data.Less(pivot, c-1); c-- { // data[c-1] > pivot
}
if b >= c {
break
}
// data[b] > pivot; data[c-1] <= pivot
data.Swap(b, c-1)
b++
c--
}
// If hi-c<3 then there are duplicates (by property of median of nine).
// Let's be a bit more conservative, and set border to 5.
protect := hi-c < 5
if !protect && hi-c < (hi-lo)/4 {
// Lets test some points for equality to pivot
dups := 0
if !data.Less(pivot, hi-1) { // data[hi-1] = pivot
data.Swap(c, hi-1)
c++
dups++
}
if !data.Less(b-1, pivot) { // data[b-1] = pivot
b--
dups++
}
// m-lo = (hi-lo)/2 > 6
// b-lo > (hi-lo)*3/4-1 > 8
// ==> m < b ==> data[m] <= pivot
if !data.Less(m, pivot) { // data[m] = pivot
data.Swap(m, b-1)
b--
dups++
}
// if at least 2 points are equal to pivot, assume skewed distribution
protect = dups > 1
}
if protect {
// Protect against a lot of duplicates
// Add invariant:
// data[a <= i < b] unexamined
// data[b <= i < c] = pivot
for {
for ; a < b && !data.Less(b-1, pivot); b-- { // data[b] == pivot
}
for ; a < b && data.Less(a, pivot); a++ { // data[a] < pivot
}
if a >= b {
break
}
// data[a] == pivot; data[b-1] < pivot
data.Swap(a, b-1)
a++
b--
}
}
// Swap pivot into middle
data.Swap(pivot, b-1)
return b - 1, c
}
|
稳定排序
sort 包中使用的稳定排序算法为 symMerge, 这里用到的归并排序算法是一种原址排序算法:首先,它把 slice 按照每 blockSize=20 个元素为一个 slice,进行插排;循环合并相邻的两个 block,每次循环 blockSize 扩大二倍,直到 blockSize > n 为止。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
| func Stable(data Interface) {
stable(data, data.Len())
}
func stable(data Interface, n int) {
blockSize := 20 // 初始 blockSize 设置为 20
a, b := 0, blockSize
// 对每个块(以及剩余不足blockSize的一个块)进行查询排序
for b <= n {
insertionSort(data, a, b)
a = b
b += blockSize
}
insertionSort(data, a, n)
for blockSize < n {
a, b = 0, 2*blockSize
// 每两个 blockSize 进行合并
for b <= n {
symMerge(data, a, a+blockSize, b)
a = b
b += 2 * blockSize
}
// 剩余一个多 blockSize 进行合并
if m := a + blockSize; m < n {
symMerge(data, a, m, n)
}
blockSize *= 2
}
}
// SymMerge merges the two sorted subsequences data[a:m] and data[m:b] using
// the SymMerge algorithm from Pok-Son Kim and Arne Kutzner, "Stable Minimum
// Storage Merging by Symmetric Comparisons", in Susanne Albers and Tomasz
// Radzik, editors, Algorithms - ESA 2004, volume 3221 of Lecture Notes in
// Computer Science, pages 714-723. Springer, 2004.
//
// Let M = m-a and N = b-n. Wolog M < N.
// The recursion depth is bound by ceil(log(N+M)).
// The algorithm needs O(M*log(N/M + 1)) calls to data.Less.
// The algorithm needs O((M+N)*log(M)) calls to data.Swap.
//
// The paper gives O((M+N)*log(M)) as the number of assignments assuming a
// rotation algorithm which uses O(M+N+gcd(M+N)) assignments. The argumentation
// in the paper carries through for Swap operations, especially as the block
// swapping rotate uses only O(M+N) Swaps.
//
// symMerge assumes non-degenerate arguments: a < m && m < b.
// Having the caller check this condition eliminates many leaf recursion calls,
// which improves performance.
func symMerge(data Interface, a, m, b int) {
// Avoid unnecessary recursions of symMerge
// by direct insertion of data[a] into data[m:b]
// if data[a:m] only contains one element.
if m-a == 1 {
// Use binary search to find the lowest index i
// such that data[i] >= data[a] for m <= i < b.
// Exit the search loop with i == b in case no such index exists.
i := m
j := b
for i < j {
h := int(uint(i+j) >> 1)
if data.Less(h, a) {
i = h + 1
} else {
j = h
}
}
// Swap values until data[a] reaches the position before i.
for k := a; k < i-1; k++ {
data.Swap(k, k+1)
}
return
}
// Avoid unnecessary recursions of symMerge
// by direct insertion of data[m] into data[a:m]
// if data[m:b] only contains one element.
if b-m == 1 {
// Use binary search to find the lowest index i
// such that data[i] > data[m] for a <= i < m.
// Exit the search loop with i == m in case no such index exists.
i := a
j := m
for i < j {
h := int(uint(i+j) >> 1)
if !data.Less(m, h) {
i = h + 1
} else {
j = h
}
}
// Swap values until data[m] reaches the position i.
for k := m; k > i; k-- {
data.Swap(k, k-1)
}
return
}
mid := int(uint(a+b) >> 1)
n := mid + m
var start, r int
if m > mid {
start = n - b
r = mid
} else {
start = a
r = m
}
p := n - 1
for start < r {
c := int(uint(start+r) >> 1)
if !data.Less(p-c, c) {
start = c + 1
} else {
r = c
}
}
end := n - start
if start < m && m < end {
rotate(data, start, m, end)
}
if a < start && start < mid {
symMerge(data, a, start, mid)
}
if mid < end && end < b {
symMerge(data, mid, end, b)
}
}
// Rotate two consecutive blocks u = data[a:m] and v = data[m:b] in data:
// Data of the form 'x u v y' is changed to 'x v u y'.
// Rotate performs at most b-a many calls to data.Swap.
// Rotate assumes non-degenerate arguments: a < m && m < b.
func rotate(data Interface, a, m, b int) {
i := m - a
j := b - m
for i != j {
if i > j {
swapRange(data, m-i, m, j)
i -= j
} else {
swapRange(data, m-i, m+j-i, i)
j -= i
}
}
// i == j
swapRange(data, m-i, m, i)
}
|
以上是稳定排序方法 Stable的全部代码。
排序 example
为应用 sort 包里排序函数 Sort(不稳定排序),我们需要让被排序的 slice 类型实现 sort.Interface接口,以整形切片为例:
1
2
3
4
5
6
7
8
9
10
11
12
| type IntSlice []int
func (p IntSlice) Len() int { return len(p) }
func (p IntSlice) Less(i, j int) bool { return p[i] < p[j] }
func (p IntSlice) Swap(i, j int) { p[i], p[j] = p[j], p[i] }
func main() {
sl := IntSlice([]int{89, 14, 8, 9, 17, 56, 95, 3})
fmt.Println(sl) // [89 14 8 9 17 56 95 3]
sort.Sort(sl)
fmt.Println(sl) // [3 8 9 14 17 56 89 95]
}
|
总结
本文主要详细介绍了我们常见的7种排序算法的原理,实现和时间复杂度分析,并阅读 Go 源码里 sort 包的实现,分析官方如何通过将以上排序算法进行组合来提高排序性能,完成生产环境的排序实践。
参考
