背景
目前在做一个消息中台,提供给业务方各种消息通道能力。我们在系统设计过程中,除了有对业务方在使用时做 Quota 限制;也有对请求做流量控制(几w+ QPS),防止并发流量上来时打垮服务。下面是个人在调研流量控制方案的一些梳理和总结。
高并发解决方案概述
并发通常是指并发访问,也就是在某个时间点,有多少个访问请求同时到来。机器的性能是有限的,如果这个量级达到一定程度,就会造成系统压力,影响系统性能。
应对高并发流量的几种解决方案:
- 流量优化: 防盗链处理
- 前端优化: 减少 HTTP 请求,合并 CSS 或 js, 添加异步请求,启用流量器缓存和文件压缩,CDN 加速,建立独立图片服务器
- 服务端优化: 页面静态化,并发处理,队列处理
- 数据库优化: 数据库缓存,分库分表,分区操作,读写分离,
- Web 服务器优化: 负载均衡, nginx 反向代理
- 服务降级: 如果不是核心链路,就把这个服务去掉
- 流量控制:限流
流量控制
高并发最有效和常用的解决方案是流量控制 ,也就是限流。为应对服务的高可用,通过对大流量的请求进行限流,拦截掉大部分请求,只允许一部分请求真正进入后端服务器,这样就可以防止大量请求造成系统压力过大导致系统崩溃的情况,从而保护服务正常可用。
常用的限流算法
计数器
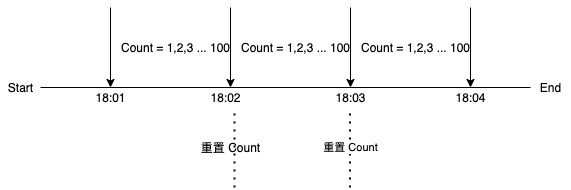
计数器是一种比较简单的限流算法,用途比较广泛,在接口层面,很多地方使用这种方式限流。在一段时间内,进行计数,与阀值进行比较,到了时间临界点,再将计数器清0。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| package counter
import (
"fmt"
"time"
)
func CounterDemo() {
// init rate limiter
limitCount := int64(100)
interval := 60 * time.Second
rateLimiter := NewRateLimiter(limitCount, interval)
for i := 0; i < 800; i++ {
if rateLimiter.Grant() {
fmt.Println("Continue to process")
continue
}
fmt.Println("Exceed rate limit")
}
}
type RateLimiter struct {
limitCount int64
interval time.Duration
requestCount int64
startAt time.Time
}
func NewRateLimiter(limitCount int64, interval time.Duration) *RateLimiter {
return &RateLimiter{
startAt: time.Now(),
interval: interval,
limitCount: limitCount,
}
}
func (rl *RateLimiter) Grant() bool {
now := time.Now()
if now.Before(rl.startAt.Add(rl.interval)) {
if rl.requestCount < rl.limitCount {
rl.requestCount++
return true
}
return false
}
rl.startAt = time.Now()
rl.requestCount = 0
return false
}
|
这种实现方式存在一个时间临界点问题:如果在单位时间 1min 内的前 1s ,已经通过了 100 个请求,那后面的 59s ,只能把请求拒绝,这种现象称为 突刺现象。
漏桶
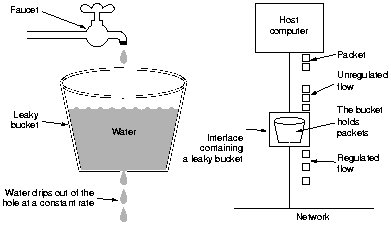
由于计数器存在突刺现象,可以使用漏桶算法来解决。漏桶提供了一种简单、直观的方法,通过队列来限制速率,可以把队列看作是一个存放请求的桶。当一个请求被注册时,会被加到队列的末端。每隔一段时间,队列中的第一个事件就会被处理。这也被称为先进先出(FIFO)队列。如果队列已满,那么额外的请求就会被丢弃(或泄露)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| package leakyBucket
import (
"fmt"
"time"
)
func LeakyBucketDemo() {
// init rate limiter
rate := int64(5)
size := int64(10)
rateLimiter := NewRateLimiter(rate, size)
for i := 0; i < 800; i++ {
if rateLimiter.Grant() {
fmt.Println("Continue to process")
continue
}
fmt.Println("Exceed rate limit")
}
}
type RateLimiter struct {
startAt time.Time
// bucket size
size int64
// now the water in bucket
water int64
// rater discharge rate
rate int64
}
func NewRateLimiter(rate, size int64) *RateLimiter {
return &RateLimiter{
startAt: time.Now(),
rate: rate, // rate of processing requests, request/s
size: size,
}
}
func (rl *RateLimiter) Grant() bool {
// calculating water output
now := time.Now()
out := int64(now.Sub(rl.startAt).Milliseconds()) * rl.rate
// remain water after the leak
rl.water = max(0, rl.water-out)
rl.startAt = now
if rl.water+1 < rl.size {
rl.water++
return true
}
return false
}
func max(a, b int64) int64 {
if a > b {
return a
}
return b
}
|
漏桶算法的优点是,它能将突发的请求平滑化,并以近似平均的速度处理。但是,瞬间高并发的流量可能会使请求占满队列,使最新的请求无法得到处理,也不能保证请求在固定时间内得到处理。
令牌桶
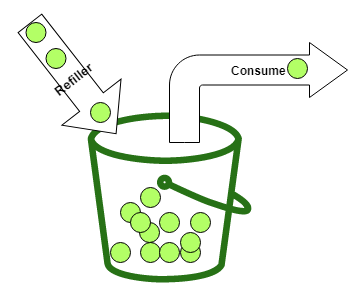
令牌桶算法是对漏桶算法的一种改进,桶算法能够限制请求调用的速率,而令牌桶算法能够在限制调用的平均速率的同时还允许一定程度的突发调用。
该算法的基本原理也很容易理解。就是有一个桶,里面有一个最大数量的 Token(容量)。每当一个消费者想要调用一个服务或消费一个资源时,他就会取出一个或多个 Token。只有当消费者能够取出所需数量的 Token 时,他才能消费一项服务。如果桶中没有所需数量的令牌,他需要等待,直到桶中有足够的令牌。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
| package tokenBucket
import (
"fmt"
"time"
)
func tokenBucketDemo() {
tokenRate := int64(5)
size := int64(10)
rateLimiter := NewRateLimiter(tokenRate, size)
for i := 0; i < 800; i++ {
if rateLimiter.Grant() {
fmt.Println("Continue to process")
continue
}
fmt.Println("Exceed rate limit")
}
}
type RateLimiter struct {
startAt time.Time
size int64
tokens int64
tokenRate int64
}
func NewRateLimiter(tokenRate, size int64) *RateLimiter {
return &RateLimiter{
startAt: time.Now(),
tokenRate: tokenRate,
size: size,
}
}
func (rl *RateLimiter) Grant() bool {
now := time.Now()
in := now.Sub(rl.startAt).Milliseconds() * rl.tokenRate
rl.tokens = min(rl.size, rl.tokens+in)
rl.startAt = now
if rl.tokens > 0 {
rl.tokens--
return true
}
return false
}
func min(a, b int64) int64 {
if a > b {
return b
}
return a
}
|
滑动窗口
漏桶和令牌桶算法存在两个缺点:
- 需要设置两个参数(平均速率和阈值),不一定容易调试好
- 涉及多个不同操作(比如漏桶算法,每次校验都需要再更新开始时间),无法原子化完成这些操作
这里推荐一种更优秀的限流算法:滑动窗口。它可以灵活地扩展速率限制,并且性能良好。 能较好解决上面这两个缺陷,同时避免了漏桶的瞬时大流量问题,以及计数器实现的突刺现象。
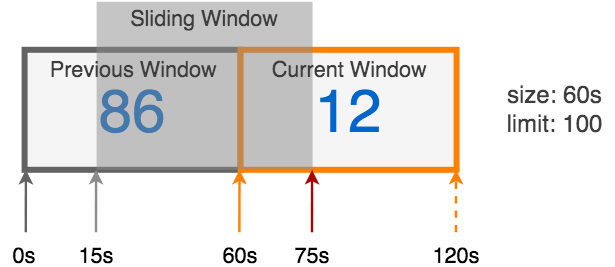
滑动窗口是把固定时间片,进行划分,并且随着时间进行移动,这样就巧妙的避开了计数器的突刺现象。也就是说这些固定数量的可以移动的格子,将会进行计数判断阀值,因此格子的数量影响着滑动窗口算法的精度。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
| package slidingWindow
import (
"fmt"
"sync"
"time"
)
func SlidingWindowDemo() {
// allow 10 requests per second
rateLimiter := NewRateLimiter(time.Second, 10, func() Window {
return NewLocalWindow()
})
if rateLimiter.Grant() {
fmt.Println("Continue to process")
} else {
fmt.Println("Exceed rate limit")
}
}
// Window represents a fixed-window
type Window interface {
// Start returns the start boundary
Start() time.Time
// Count returns the accumulated count
Count() int64
// AddCount increments the accumulated count by n
AddCount(n int64)
// Reset sets the state of the window with the given settings
Reset(s time.Time, c int64)
}
type NewWindow func() Window
type LocalWindow struct {
start int64
count int64
}
func NewLocalWindow() *LocalWindow {
return &LocalWindow{}
}
func (w *LocalWindow) Start() time.Time {
return time.Unix(0, w.start)
}
func (w *LocalWindow) Count() int64 {
return w.count
}
func (w *LocalWindow) AddCount(n int64) {
w.count += n
}
func (w *LocalWindow) Reset(s time.Time, c int64) {
w.start = s.UnixNano()
w.count = c
}
type RateLimiter struct {
size time.Duration
limit int64
mu sync.Mutex
curr Window
prev Window
}
func NewRateLimiter(size time.Duration, limit int64, newWindow NewWindow) *RateLimiter {
currWin := newWindow()
// The previous window is static (i.e. no add changes will happen within it),
// so we always create it as an instance of LocalWindow
prevWin := NewLocalWindow()
return &RateLimiter{
size: size,
limit: limit,
curr: currWin,
prev: prevWin,
}
}
// Size returns the time duration of one window size
func (rl *RateLimiter) Size() time.Duration {
return rl.size
}
// Limit returns the maximum events permitted to happen during one window size
func (rl *RateLimiter) Limit() int64 {
rl.mu.Lock()
defer rl.mu.Unlock()
return rl.limit
}
func (rl *RateLimiter) SetLimit(limit int64) {
rl.mu.Lock()
defer rl.mu.Unlock()
rl.limit = limit
}
// shorthand for GrantN(time.Now(), 1)
func (rl *RateLimiter) Grant() bool {
return rl.GrantN(time.Now(), 1)
}
// reports whether n events may happen at time now
func (rl *RateLimiter) GrantN(now time.Time, n int64) bool {
rl.mu.Lock()
defer rl.mu.Unlock()
rl.advance(now)
elapsed := now.Sub(rl.curr.Start())
weight := float64(rl.size-elapsed) / float64(rl.size)
count := int64(weight*float64(rl.prev.Count())) + rl.curr.Count()
if count+n > rl.limit {
return false
}
rl.curr.AddCount(n)
return true
}
// advance updates the current/previous windows resulting from the passage of time
func (rl *RateLimiter) advance(now time.Time) {
// Calculate the start boundary of the expected current-window.
newCurrStart := now.Truncate(rl.size)
diffSize := newCurrStart.Sub(rl.curr.Start()) / rl.size
if diffSize >= 1 {
// The current-window is at least one-window-size behind the expected one.
newPrevCount := int64(0)
if diffSize == 1 {
// The new previous-window will overlap with the old current-window,
// so it inherits the count.
newPrevCount = rl.curr.Count()
}
rl.prev.Reset(newCurrStart.Add(-rl.size), newPrevCount)
// The new current-window always has zero count.
rl.curr.Reset(newCurrStart, 0)
}
}
|
集群限流
上面的4种限流方式,更多是针对单实例下的并发场景, 下面介绍几种服务集群的限流方案:
Nginx 限流
Nginx 官方提供的限速模块使用的是 漏桶算法,保证请求的实时处理速度不会超过预设的阈值,主要有两个设置:
- limit_req_zone: 限制 IP 在单位时间内的请求数
- limit_req_conn: 限制同一时间连接数
Redis 限流
通过 Redis 提供的 incr 命令,在规定的时间窗口,允许通过的最大请求数
分布式滑动窗口限流
Kong 官方提供了一种分布式滑动窗口算法的设计, 目前支持在 Kong 上做集群限流配置。它通过集中存储每个滑动窗口和 consumer 的计数,从而支持集群场景。这里推荐一个 Go 版本的实现: slidingwindow
其他
另外业界在分布式场景下,也有 通过 Nginx+Lua 和 Redis+Lua 等方式来实现限流
总结
本文主要是自己在学习和调研高并发场景下的限流方案的总结。目前业界流行的限流算法包括计数器、漏桶、令牌桶和滑动窗口, 每种算法都有自己的优势,实际应用中可以根据自己业务场景做选择,而分布式场景下的限流方案,也基本通过以上限流算法来实现。在高并发下流量控制的一个原则是:先让请求先到队列,并做流量控制,不让流量直接打到系统上。
参考
- 对高并发流量控制的一点思考
- How to Design a Scalable Rate Limiting Algorithm
- slidingwindow
- Token Bucket Rate Limiting
- Rate limiting Spring MVC endpoints with bucket4j
- How we built rate limiting capable of scaling to millions of domains
