Go 程序性能分析

文章目录
背景
Go 是 GC 类语言,内存自动回收。 如果程序中已动态分配的堆内存由于某种原因程序未释放或无法释放, 这时候就会产生内存泄露, 造成系统内存浪费,导致程序运行减慢甚至系统 OOM。类似地,程序在运行过程中可能会出现 CPU 问题。
性能分析是排查内存泄露等问题的常见手段, 可以让我们了解和捕获到程序堆内存和 Profile 信息, 方便定位问题。Go 原生提供了丰富的分析工具,下面是通过几个内存泄露的案例对 Go 程序做性能分析,并介绍相关工具原理和细节。
GODEBUG
通过 GODEBUG 开启 debug 模式后,可做内存 trace 和调度器的 trace, runtime 每次垃圾回收时会记录 GC 信息。
设置内存追踪模式: GODEBUG=gctrace=1 go run example.go
进程结束后就可以打印 GC 信息(这里 gctrace 只有在程序结束后才会打印 GC 信息, 编译后的程序是守护模式的常驻进程,没有显示 gctrace 信息)
官方 runtime 对 gctrace 做了详细的说明:
gctrace: setting gctrace=1 causes the garbage collector to emit a single line to standard error at each collection, summarizing the amount of memory collected and the length of the pause. Setting gctrace=2 emits the same summary but also repeats each collection. The format of this line is subject to change.
也就是说垃圾收集器在每次触发 GC 时就会打印日志。
GC 日志说明
gctrace 每一行打印的日志格式如下:
| |
每一个变量的具体定义:
- {0}: gc 运行次数
- {1}: 程序已运行的时间
- {2}: gc 占用程序 CPU 的百分比
- {3}: 执行时间,包括程序延迟和资源等待
- {4}: 也是执行时间, 一般看这个
- {5}: CPU clock
- {6}: CPU clock
- {7}: GC 启动前的堆内存
- {8}: GC 运行后的堆内存
- {9}: 当前堆内存
- {10}: GC 目标
- {11}: 进程数
举个例子,有下面一条 gctrace 日志:
| |
每个 trace 元信息对应的含义
- gc 3:第 3 次 GC
- @2.387: 当前是程序启动后的 2.387s
- 0%: 程序启动后到现在共花费 0% 的时间在 GC 上
- 0.021+23+0.053 ms clock
- 0.021:表示单个 P 在 mark 阶段的 STW 时间
- 23:表示所有 P 的 mark concurrent(并发标记)所使用的时间
- 0.053:表示单个 P 的 markTermination 阶段的 STW 时间
- 0.086+0.011/17/6.0+0.21 ms cpu
- 0.086 表示整个进程在 mark 阶段 STW 停顿的时间
- 0.011/17/6.0:0.011 表示 mutator assist 占用的时间,17 表示 dedicated + fractional 占用的时间,6.0 表示 idle 占用的时间
- 0.21ms:0.21 表示整个进程在 markTermination 阶段 STW 时间
- 165->165->127 MB:
- 165:表示开始 mark 阶段前的 heap_live 大小
- 165:表示开始 markTermination 阶段前的 heap_live 大小
- 127:表示被标记对象的大小。
- 166 MB goal:表示下一次触发 GC 回收的阈值是 166 MB
- 4 P:本次 GC 一共涉及 4 个 进程
涉及到一些 GC 过程的术语和深层细节, 可以参考:用 GODEBUG 看 GC
演示
下面是一块存在内存泄露的代码段,通过 gctrace, 我们来看下每次 GC 时堆内存的变化 :
| |
执行 GODEBUG=gctrace=1 go run memory_tracing.go, 查看运行时的内存情况(图一):
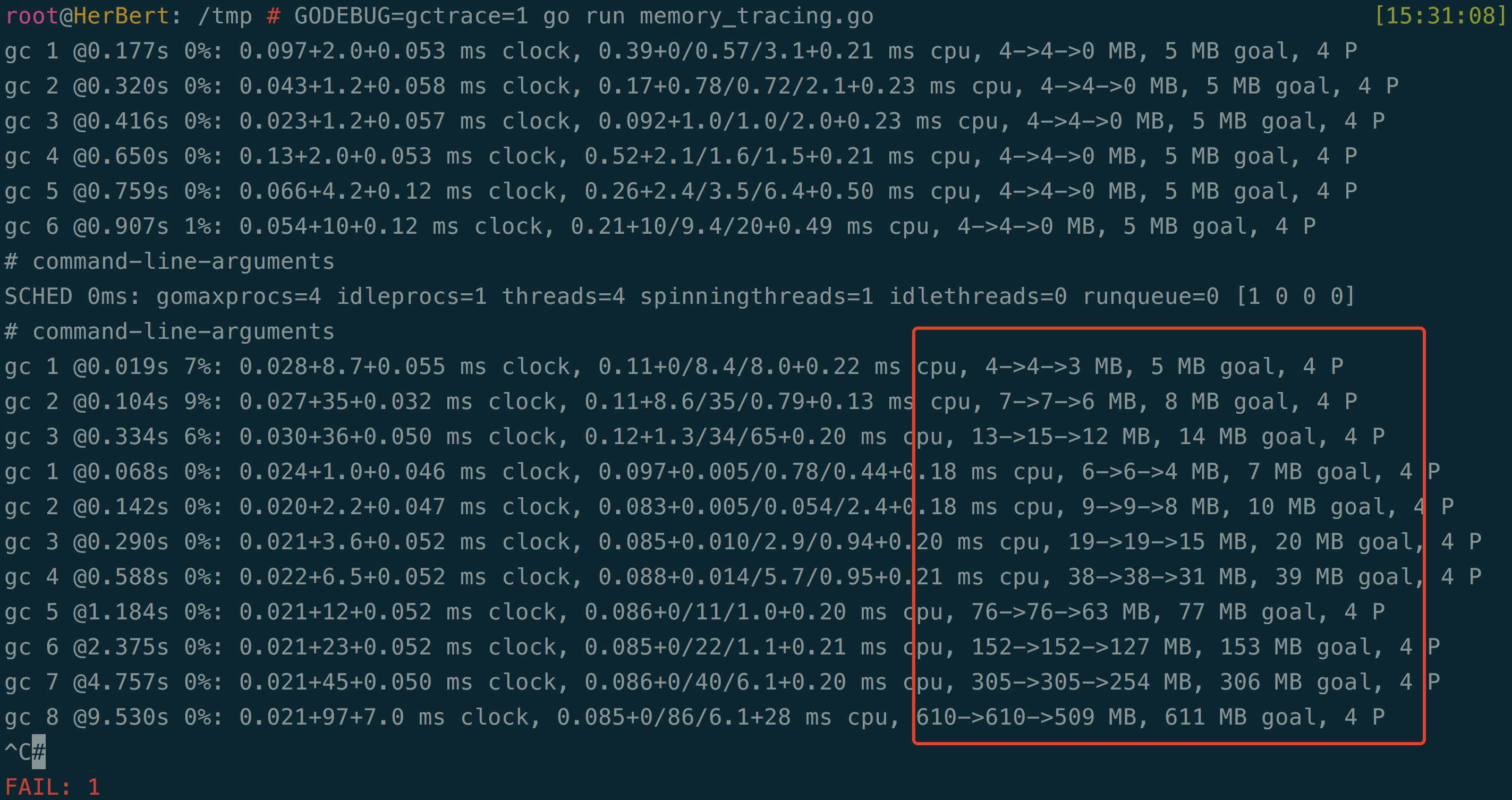
上图最后一行的 trace 日志:表示第 8 次 GC, 当前是程序启动后的 9.530s, 本次 GC 占用 0% 时间。 GC 前占 610M 内存,GC 后占 610M 内存,当前堆内存 509M。下一次触发 GC 的阈值是 611 MB。 本次 GC 一共涉及到 4个进程。
可以看到程序在运行过程中, 后面的 GC ,堆内存在逐渐增大, 触发 GC 后堆内存大小并没有稳定在一个值或者减少,比如第8次 GC, 本次 GC 没有占用程序运行时间(0%), GC 后内存 509MB 比上一次 GC 后增大 382MB, 内存释放的速度慢于内存增长速度,这是一个比较明显的内存泄露场景。
GOGC 和 Scheduler Trace
GODEBUG 还支持设置以下变量:
GOGC: 改变堆增长方式 —— 设置初始的 GC 目标百分比。当新分配内存,与上一次采集后剩余的实时数据的比例达到这个百分比时,才会触发一次 GC。默认值是 GOGC=100。设置
GOGC=off则完全禁用垃圾收集器。 举个例子,比如GODEBUG=gctrace=1 GOGC=200 go run memory_tracing.go, 表示堆内存增长到 200% 会触发一次 GC, 打印一条 trace 日志。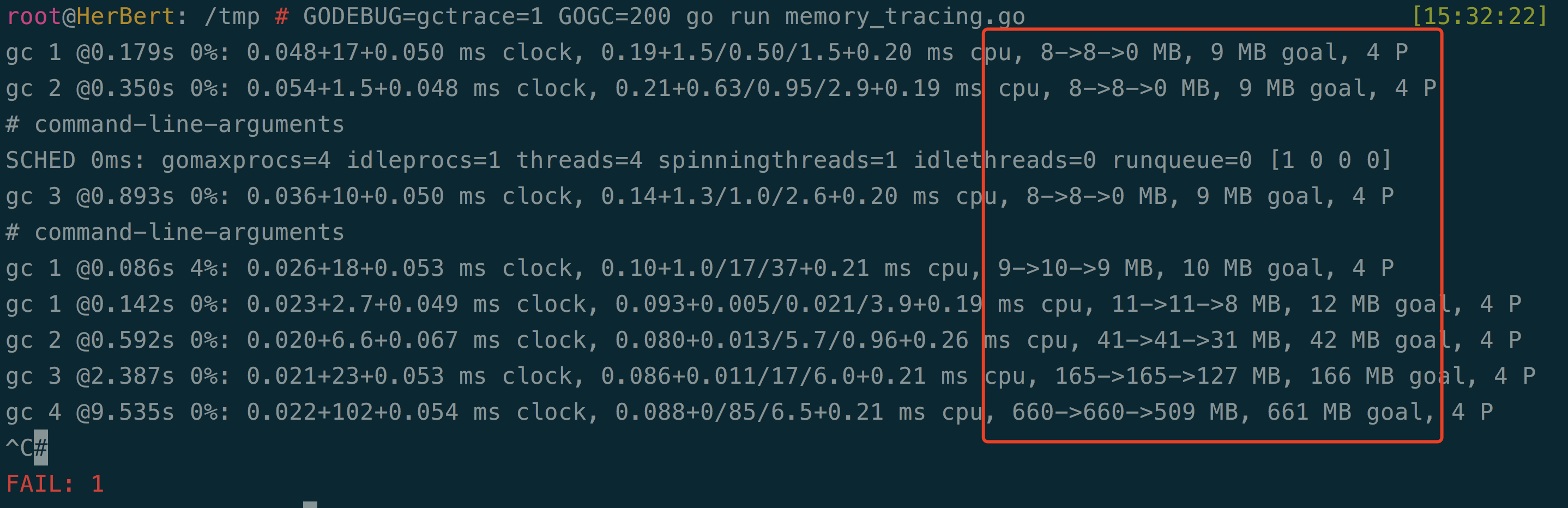
和 图一 比较, 可以看到内存 8M 左右时触发 GC (200%)
schedtrace:设置
schedtrace=X,每 X 毫秒打印一次调度器状态 —— 包括调度器、处理器、线程和 goroutine: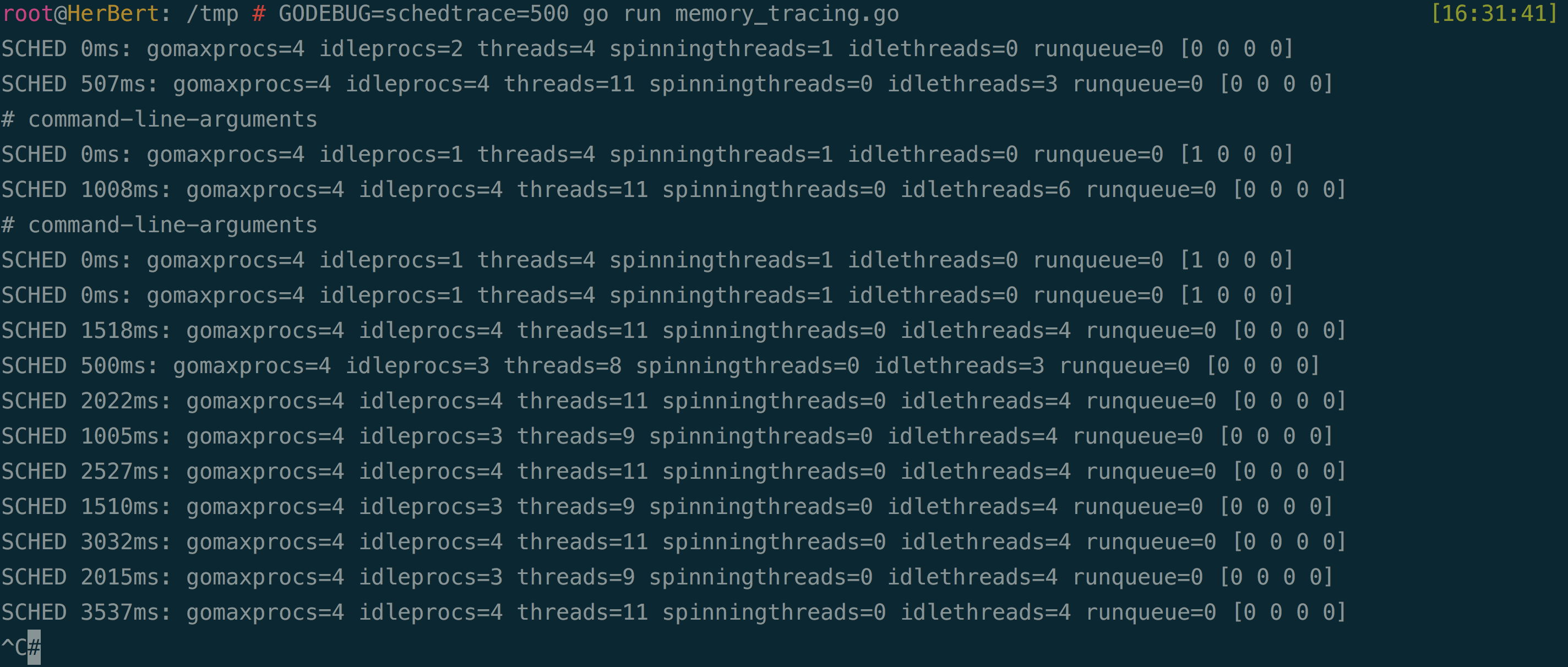
PPROF
上面通过 GODEBUG 设置 gctrace 参数,来分析 Go 程序在执行过程中的运行情况, 并对 trace 日志含义做了说明。通过一段内存泄露的样例,来分析 GC 过程的堆内存变化。但是可以看到, 仅仅是通过 gctrace, 只能大致确定内存泄露问题是否存在,作用有限(比如项目非常庞大复杂,或高并发程序)。 Go 官方提供了更加强大的内存分析利器: pprof 。通过 pprof 对 Web应用和服务进行配置,以查看性能或内存被占用的确切位置。
原理
Go 的 runtime 包 支持收集和生成 pprof 可视化工具 所定义格式的 profiling 文件(采样数据)。
采样数据主要有三种采集方式:
- runtime/pprof: 在程序里埋点, 调用
runtime.StartCPUProfile和runtime.StopCPUProfileAPI, 生成采样数据 - net/http/pprof : import 到程序后注入
/debug/pprof/接口, 通过 HTTP 服务器采集数据,以 runtime/pprof 实现 - go test: 一般对函数进行测试并生成采样数据, 如
go test -bench=. -cpuprofile=cpu.prof
runtime/pprof 提供了多种类型的采样, 官方的支持如下:

捕获到采样数据,导入到 pprof 可视化工具,就可以进行我们想要的性能分析。
演示
还是用上面的代码段为例子,注入了 net/http/pprof ,来支持 prof 数据采集,memory_tracing_01.go 代码如下:
| |
执行 go run memory_tracing_01.go 让程序运行,在浏览器输入 http://localhost:8080/debug/pprof/, 可以看到 pprof 界面:
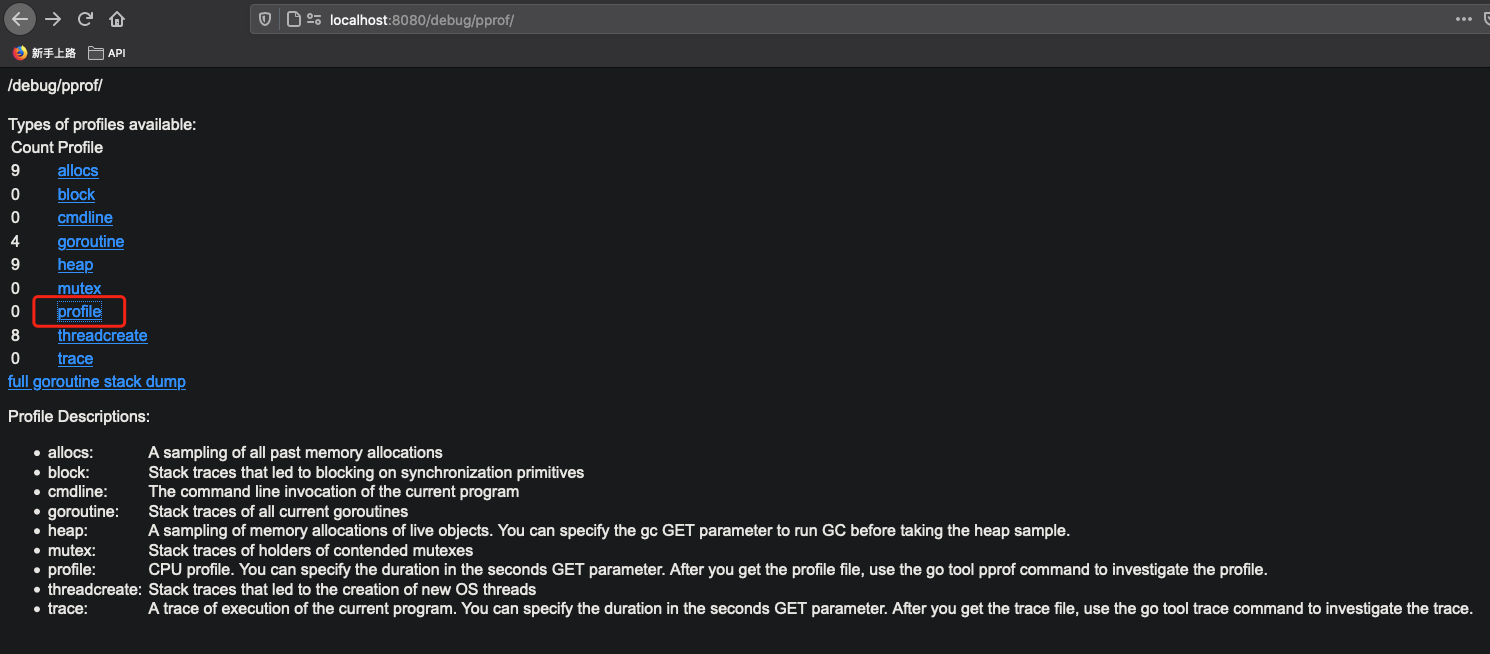
因为程序存在内存泄露,刷新页面能发现 allocs 和 heap 指标一直在增长。
可以直接在界面提供的采样数据进行问题定位,但是分析起来比较麻烦, 这里选择直接下载 heap 的采样数据(采样 20s):
| |
内存分析
拿到性能采样数据后, 下一步就是通过 go tool pprof 进行内存分析。
关于 pprof 的使用姿势,这里推荐两篇很详细的博客:
现在网上相关博客和文档非常的多,这里总结了大部分文章推荐的使用姿势:
go tool pprof XXX.prof直接进入调试终端- svg/pdf 拿到 函数调用的流程图
- topN -cum 按资源占用递减排序
- list FuncXXX, 然后看具体函数里那个点 占最多 CPU, 或者吃最多内存
- 安装 Uber 的 go-torch, 生成一张火焰图,进行下一步分析
其实可以发现,上面这一套下来学习成本有点高, 需要在学习采样 profile 数据后,再了解3~4个左右的步骤,才能定位到程序在哪里出现了问题。但是一般线上程序的内存泄露,CPU 飙升或者 goroutine 泄露等紧急问题,如果不知道如何使用 pprof, 一时半刻解决不了是挺严重的。所以是否有更直接简单的姿势,来提高问题定位的效率?
答案是有的。go tool pprof 目前已经支持 UI , 通过在 Web 界面上的操作,不需要学习指令就可以更快地做性能分析(google 的 pprof, 也提供强大易上手的 UI 支持)。
以刚采样到的 memory_tracing_01.prof 为例, 执行:
| |
在浏览器输入 pprof UI 地址:http://localhost:8080/ui/
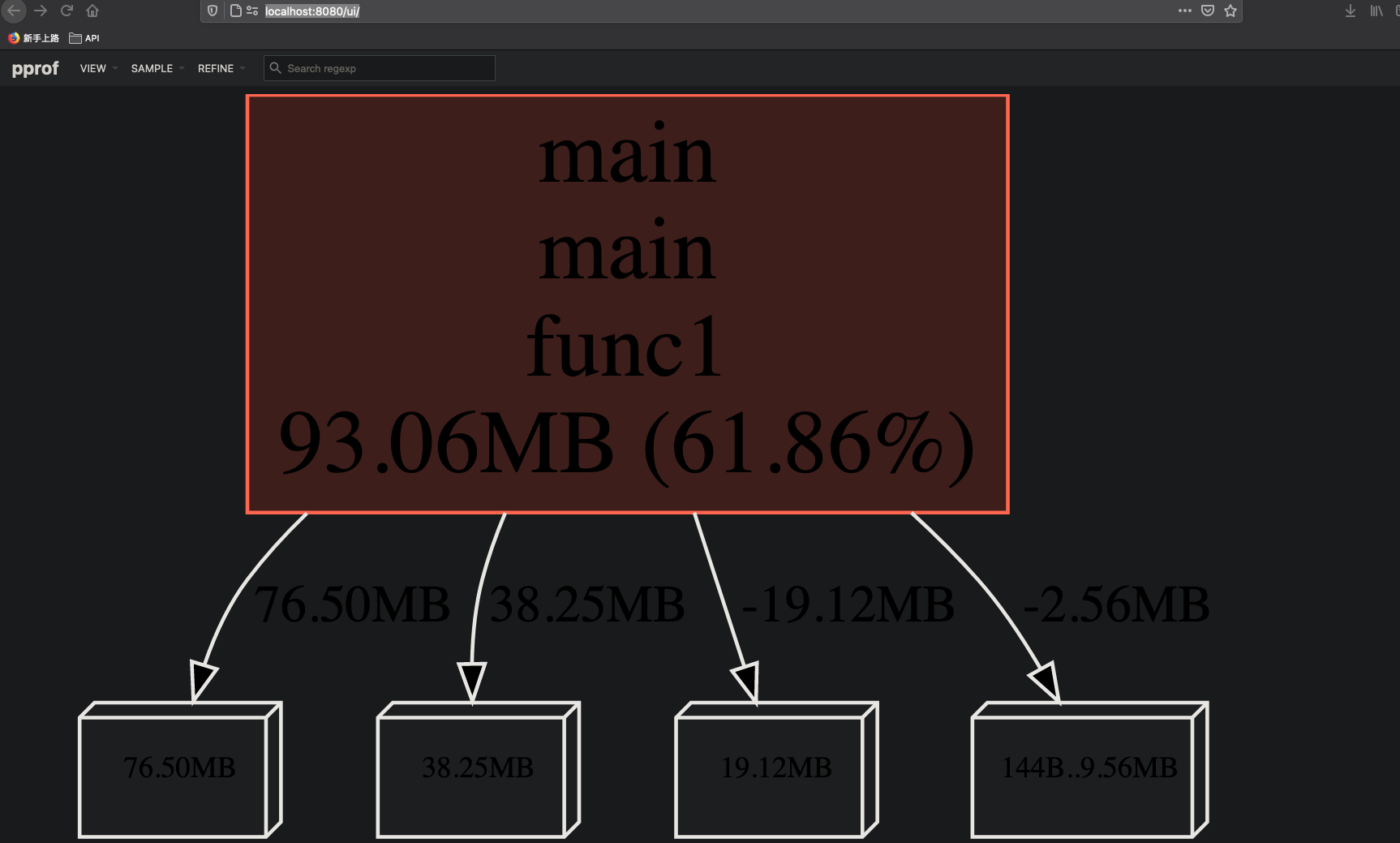
首页是函数调用流程图,可以直观地看到 main.main.founc1 占用了 93.06MB 内存, 底下是内存具体分配。可以知道大部的内存消耗在 func1 函数里。
点击菜单栏 VIEW -> Source,可以查看具体到哪一行代理,占用多少内存 (以占用内存多少倒序):
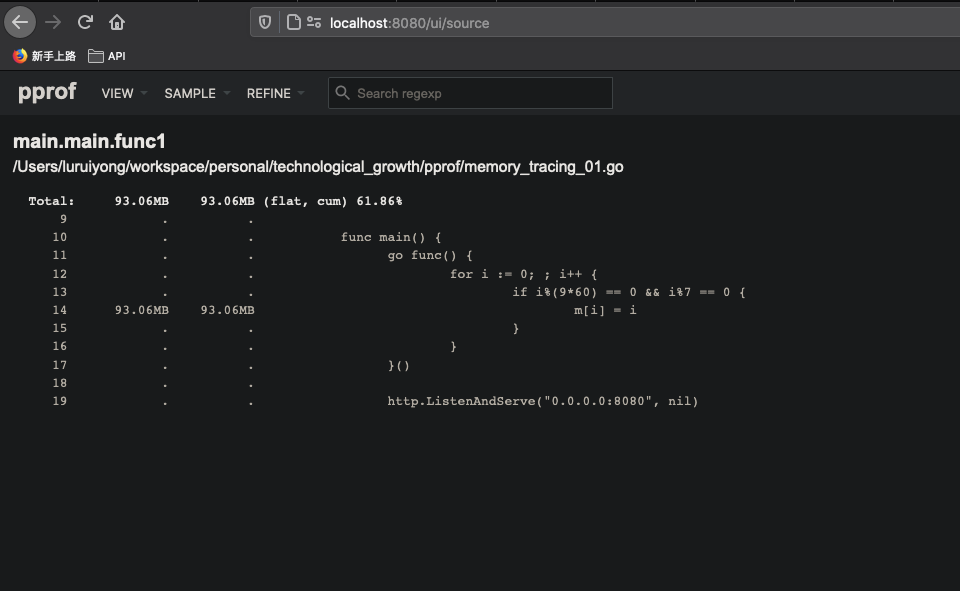
由上图 line 14 可以明显看到, m 这个 map 占用了 93.06MB 的内存, 占采样到的内存样本的100%。因此,可以知道内存泄露问题是 m 导致的。
pprof 的 Web 界面另一大利器是 支持火焰图(Flame Graph),可以更直观查看整个程序函数调用和资源使用。与go-torch 相比,它最大优点是动态的, 调用顺序由上到下(A -> B -> C -> D),每一块代表一个函数,越大代表占用 CPU 的时间更长(或占用更多内存)。支持点击块深入进行分析!
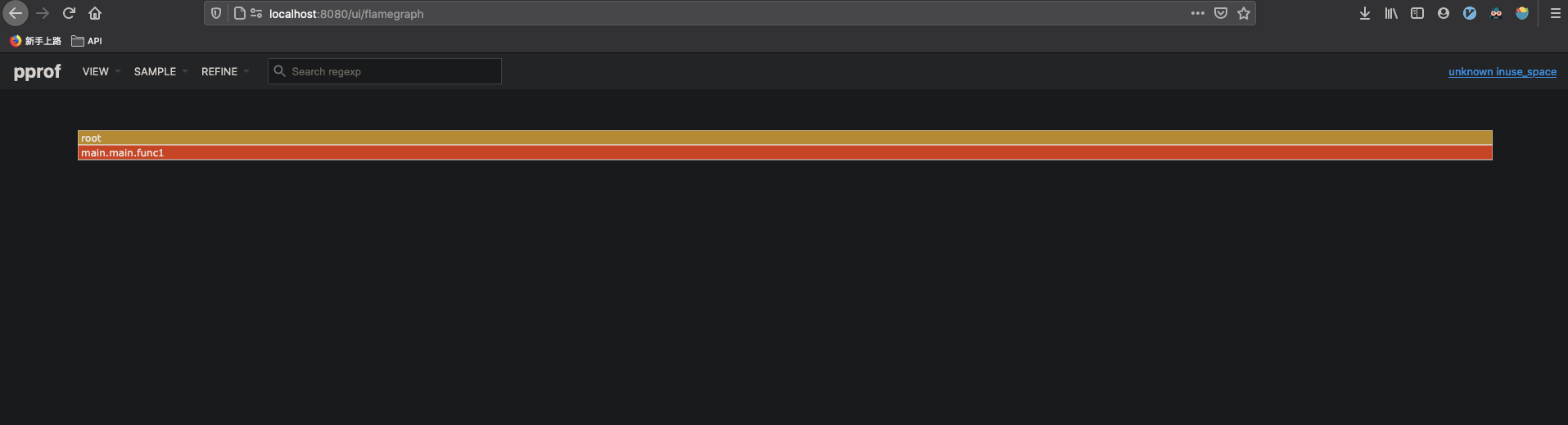
至此, 已经通过 go tool pprof 完成内存泄露的定位, 下一步要做的是解决 m 的内存问题, 这里不讨论优化。
除了上面提到的 Graph、 Flame Graph 和 Source, Web 界面还支持 Top、 Peek 和 Disassemble 的数据可视化。
net/http/pprof 的缺陷和解决
现在基本很多项目会通过引入 net/http/pprof 进行数据采样和性能分析, 虽然 pprof 做 profiling 不会增加很多开销,但也存在一些缺陷:
- 暴露了 /debug 的 API 路由。 黑客可以通过发送长时延的 profiling 查询请求,来影响整体应用性能。
- 采样的数据暴露了应用内部细节,不应该对外展示。
- 如果应用是一个 offline worker, 引入一个 pprof HTTP Server 无异于增加了安全风险
net/http/pprof 带来的一些安全问题, 有以下一些解决方案:
- 确保只有经过授权的请求才能采集 profile 数据
- 可以在应用程序前加层反向代理来限制访问,或者将 pprof 服务器从主服务器上移出, 重定向到不同 TCP 端口,通过 ACL 允许其他用户访问
- 使用其他方式采样 profile 数据, 再通过 pprof 进行分析
总结
本文围绕一个简单内存泄露的例子, 来展开介绍如何对 Go 程序做性能分析定位问题,详细说明 GODEBUG 和 PPROF 的原理和一些使用姿势: GODEBUG 更多是进行 Profile tracing, 打印 gc 时日志和 schedtrace, PPROF 作为官方的分析工具来定位问题。并介绍go tool pprof 通过 Web 界面来更清楚直接地分析问题, 最后是说明引入 net/http/pprof 存在的一些安全缺陷和对应解决方案。
本篇虽然只是一个简单内存泄露展开,但类似像 CPU 飙升的问题也可以是同一个思路。 以上仅仅是性能分析的冰山一角, 关于这块有非常多的细节和知识。